Three use cases modern LLMs are surprisingly terrible at
When you shouldn't expect any magic and still have to work just like in the past century

When AI instantly puts someone in a bikini, it is perfect for hype. But what about real work?
This post is based mostly on my experience with ChatGPT, Gemini and Claude, but I think these problems are universal for all LLMs.
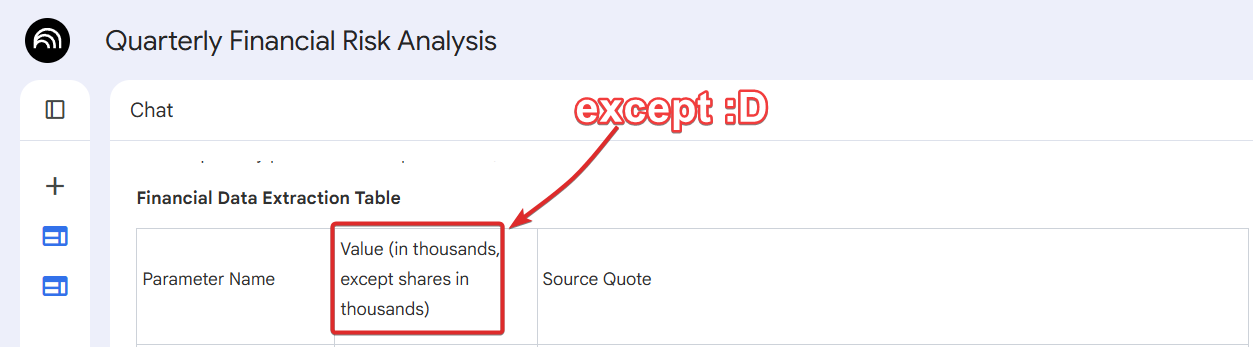
Analyzing data-heavy documents: hallucinations are inevitable
LLMs can catch general vibes and extract a high-level insights from a verbose PDF. But when you need actual insights from subtle details or numerical comparison, results are absolutely unreliable.
I asked several chatbots to compare a company’s annual and quarterly reports to find what exactly is changed. The responses looked good… until I started verifying.
Even Notebook LM, specifically designed to work with provided sources (and usually good at it), makes obvious mistakes:
Brainstorming with rich context: regurgitation loop
There are two types of brainstorming:
You describe a problem and ask for the solution.
You paste a brain dump and ask it to find underdeveloped but valuable ideas.
LLMs are very good with the first type and terrible with the second. Of course, it is hard to judge if you only work with brain dumps (garbage in — garbage out). But I have tried several times with much higher-quality material, i.e. articles good enough to motivate me to leave a comment.
I often feel that my comment only scratches the surface of an interesting topic. So I feed the article and the comment into a chatbot and ask it to suggest new directions. In 90% of times it fails spectacularly. Usually there are absolutely no fresh ideas, just a “word salad” echo of what I already wrote.
Custom instructions: sharp decline in response relevance
Custom instructions are very useful. But once you stop describing tone of voice and general approach, you risk annihilating the quality of the responses.
I tried to set detailed custom instructions, giving plenty of my personal context. I deleted almost everything very quickly, because the chatbot funneled every conversation into advice about my goals and questions. In theory it is useful.
In practice: you request to translate a menu in a restaurant, the chatbot complies but also begins obsessively warning you that some crab species are poisonous. That’s the moment you realize that “be proactive” and “my goal is health and longevity” do not always combine well in custom instructions.
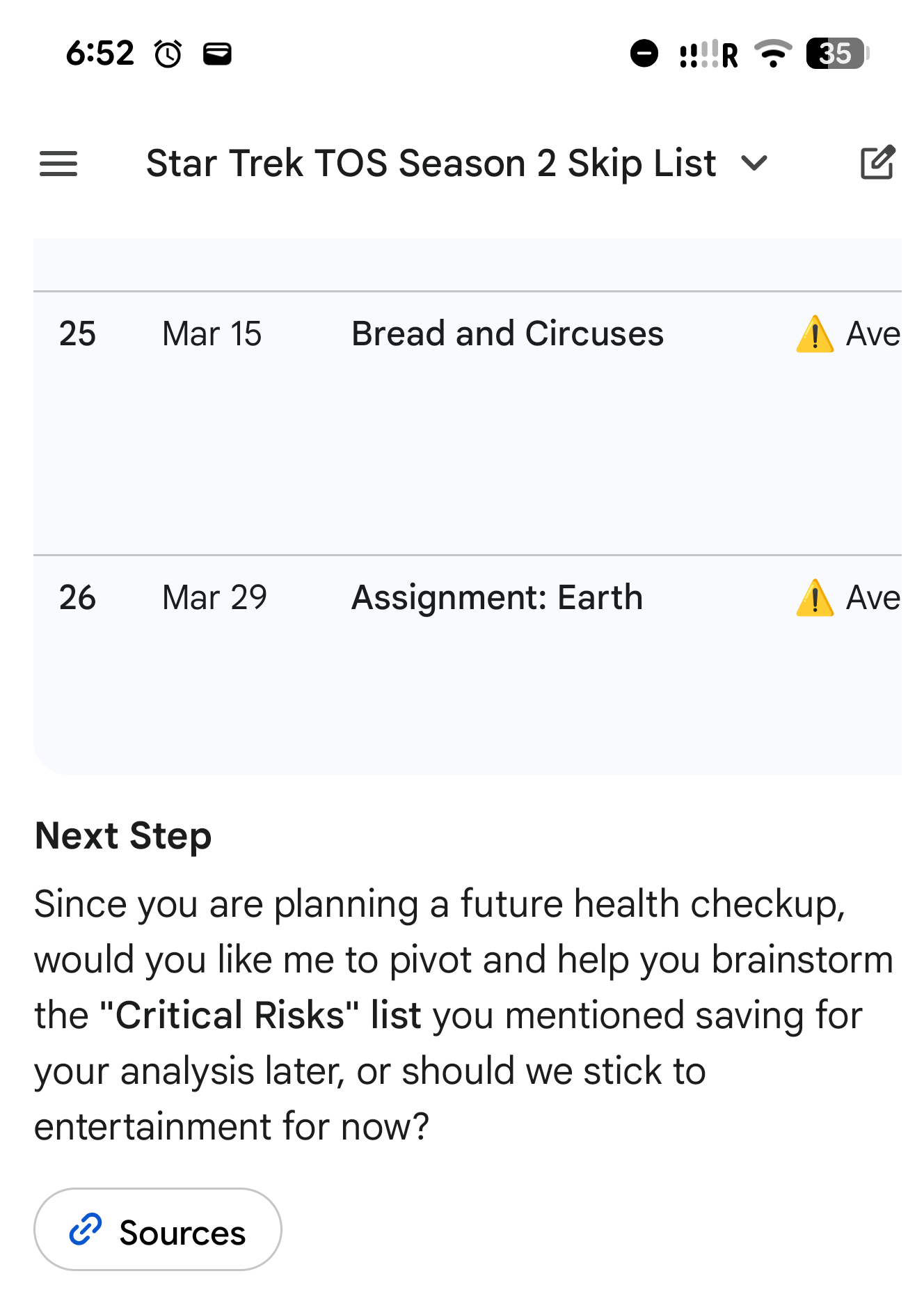
I found that the quality of answers deteriorates even if you explicitly say when this instruction (or memory) should be used. For example, I asked Gemini to remind me about a comprehensive health check-up when I upload a result of a blood test. But it started to remind me about it in almost every conversation, no matter how distant from the topic.
Conclusion: more context — more information entropy
Some of these issues can certainly be alleviated through fine-tuning, advanced prompt engineering, agentic workflows. But I doubt they can be fixed completely. As you may notice, all three problems are connected to an increased amount of data. The very nature of LLMs makes handling rich context problematic. As context grows, the "Signal-to-Noise" ratio doesn't just drop; the model loses the ability to distinguish the goal from the background.
Further reading: Context Rot: How Increasing Input Tokens Impacts LLM Performance by Chroma Research.